
Enjoy a free 30-day trial of our
data validation software.Experience the power of trusted data
solutions today, no credit card required!Enjoy a free 30-day trial of our
data validation software.Experience the power of trusted data
solutions today, no credit card required!Enjoy a free 30-day trial of our
data validation software.Experience the power of trusted data
solutions today, no credit card required!Enjoy a free 30-day trial of our
data validation software.Experience the power of trusted data
solutions today, no credit card required!
Data matching
Connect, deduplicate, and unify data across systems to create a single, trusted view
Learn more nowUnify and deduplicate customer data
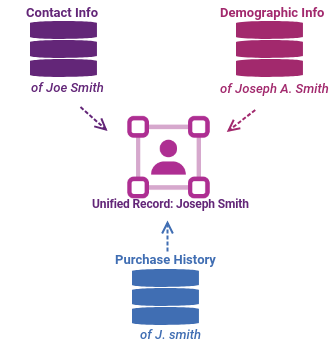
Customer data rarely lives in one place. It’s spread across CRM systems, operational platforms, legacy databases, and digital channels—often duplicated, inconsistent, or incomplete. Without effective data matching, organizations struggle to create an accurate view of their customers.
Data matching software identifies, links, and consolidates records from multiple data sources into a single, trusted customer view. By intelligently matching data across systems, it eliminates duplicates, reduces fragmentation, and improves overall data quality.
Using advanced matching techniques—including fuzzy matching and multicultural intelligence—it connects records even when data contains errors, missing information, name variations, or formatting inconsistencies.
The result is cleaner data, more efficient operations, and greater confidence in analytics, compliance, marketing, and customer experience initiatives.
Data matching is just one piece of your overall data quality program.
Combining customer data into one file makes it easier to find and use customer information. That data still needs to be accurate to be useful, and data matching software is only effective if the data you have is correct. A complete data quality strategy uses matching and validation to make sure data is accurate and up-to-date. If your data is accurate, you can look for patterns and create insights to improve your business. Discover how we can help you create a holistic data quality management strategy that includes data matching.
Data quality starts with clean data.
Manage data effectively.
Uncover possibilities from within.