NameSearch is Experian Data Quality’s premier matching solution that can accurately and efficiently identify duplicates within your systems. NameSearch uses fuzzy matching to identify records that lead to the same individual, despite the misspellings, nicknames, typos, extra, or missing information across a single or multiple databases. It’s useful for organizations in any vertical that might require a matching solution, and, because of that, it is highly customizable. The matching process consists of five preparatory steps, four of which can be altered right in the product’s settings. In addition to the steps being customizable, NameSearch can adapt different rule-sets for different types of data entered.
Each integration of NameSearch is unique. Because of the flexibility of the rule base, customers can easily mold the rules to their needs. A customer who handles a lot of California addresses, for example, may want to remove specific default noise words like “villa” that appear frequently. Another example would be that a customer who works with many international names would likely want to use a phonetic algorithm built for additional languages rather than strictly English.
The four preparatory steps changeable within the settings of NameSearch include sanitization, phrase replacement, word recognition, and phonetic tokenization. Of these four, sanitization, phrase replacement, and word recognition allow for direct manipulation of the rule. Users can add or remove different input/output combinations as they deem necessary.
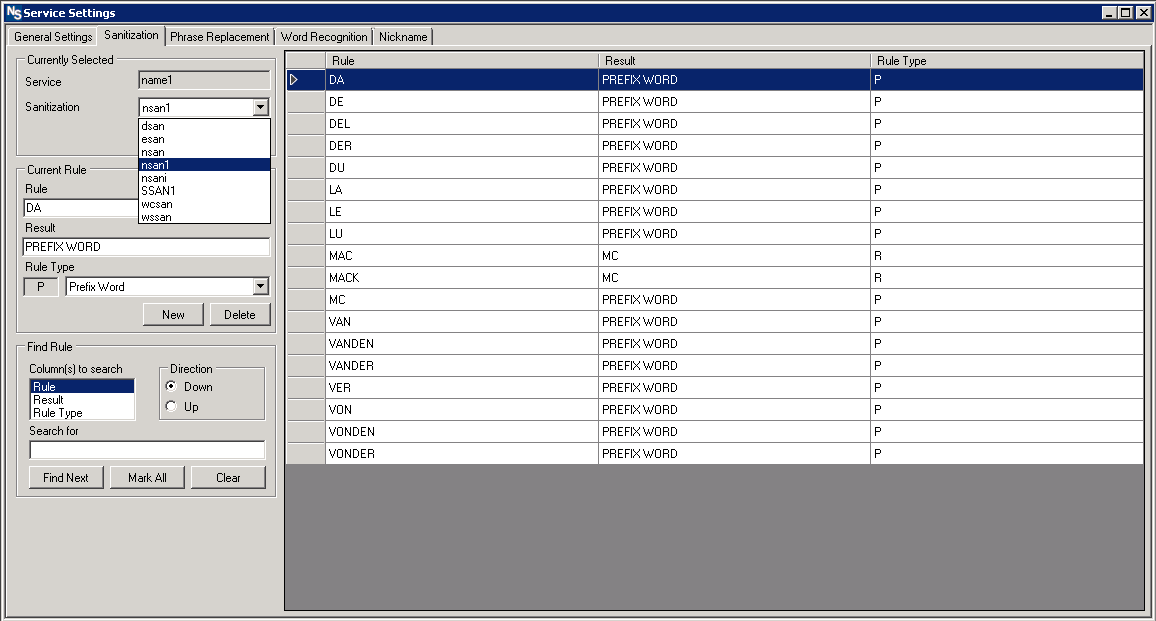
1. The sanitization step uses a ruleset to remove “noise” words and characters. This allows the rules to designate noise words, prefix words, or force a word to be recognized as a “non-major” word, meaning it will be compared as secondary instead of the primary weight for the field.
*Note: sanitization occurs in two steps:
- Step 1: Go over custom rules
- Step 2: Remove special characters ( !, @, #, $, %, ^, &, *, (, ), -, _, +, etc.)
Because of this, the user can make custom replacements for special characters before they are removed. Ex. Replace any instance of “!” with “Not “ before proceeding to step 2.
2. The phrase replacement step uses custom rules to expand abbreviations, provide alternate phrasing, etc. This stage serves as a standardization phase that allows for the recognition and expansion of abbreviations and acronyms.
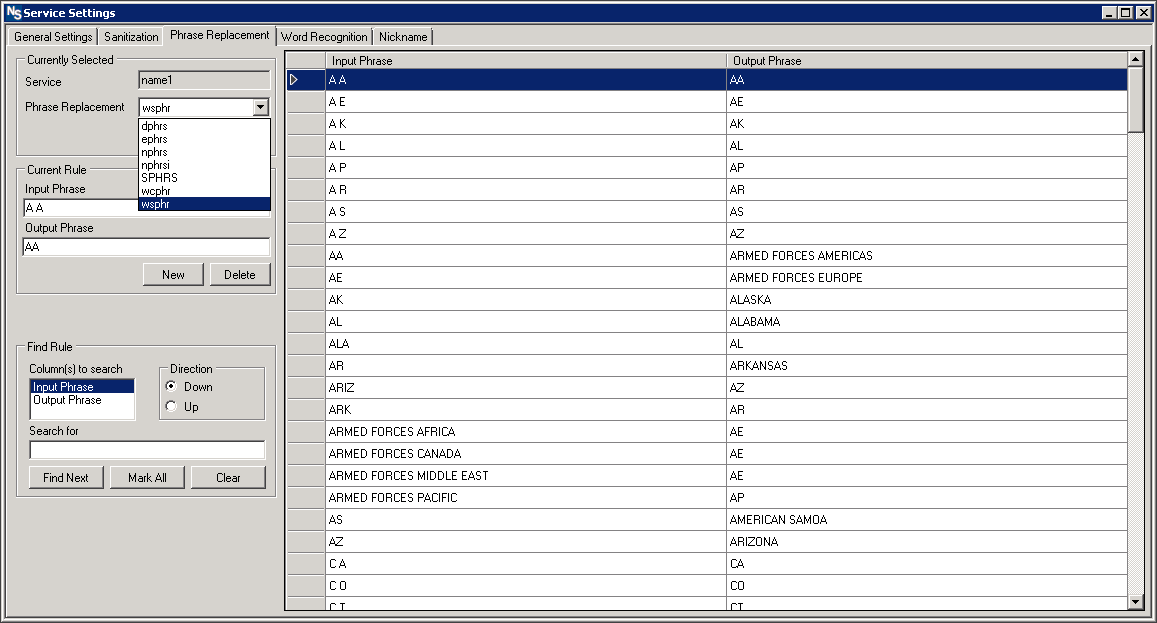
Phrase replacement ONLY allows for replacement, not for removal of duplicate or unwanted terms.
3. The word recognition step uses custom rules to designate potential word “meanings” as well as allowing for final removal of words in cases where they are deemed unnecessary.
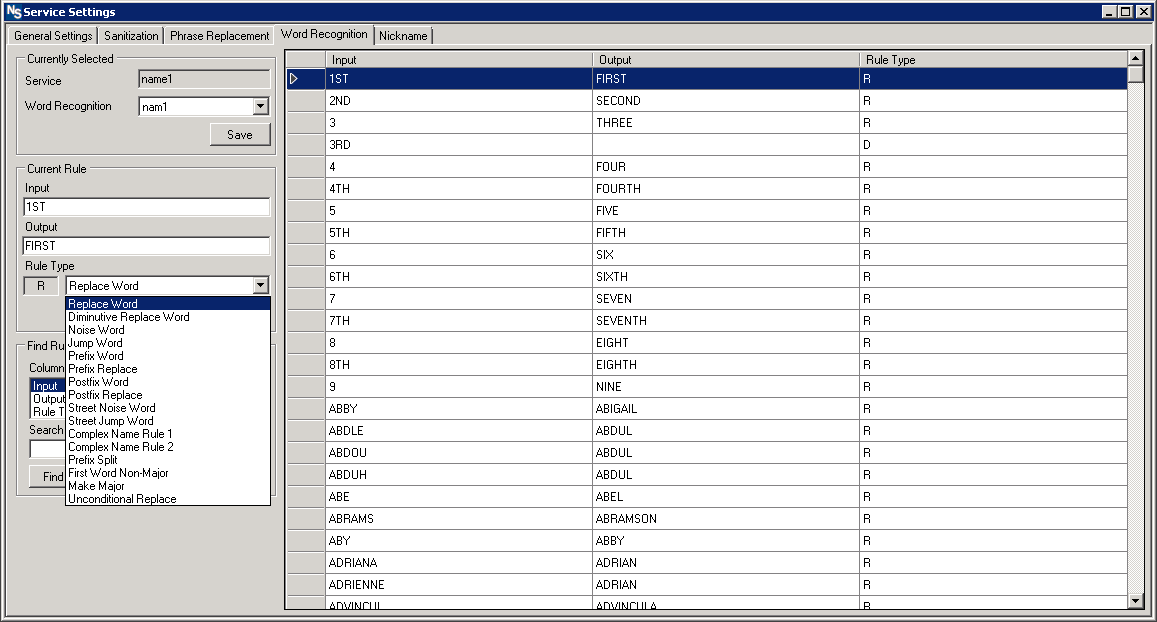
This step is the final chance for word removal and allows the user to force the recognition of specific words as the “major”(primary comparison weight) word to compare.
4. Phonetic tokenization is the final changeable step. Phonetic tokenization doesn’t allow for direct manipulation of the rule set but it does have settings to allow for decisions around how strict of a match the user wants to use.
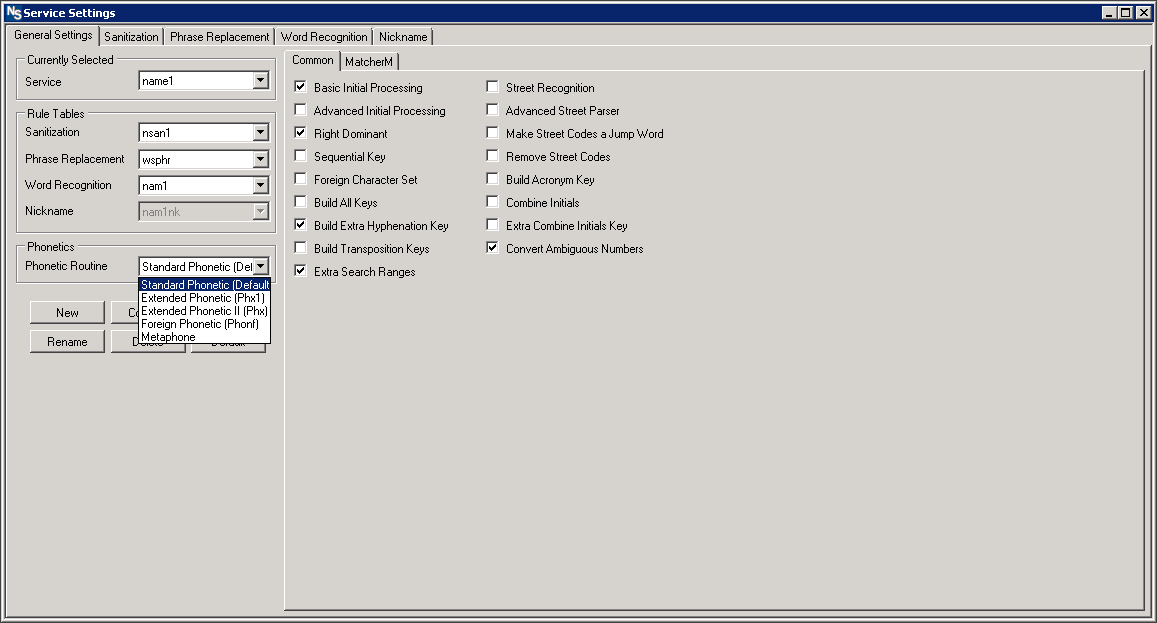
5. The fifth step, key and range generation, cannot be changed via settings; however, that doesn’t mean it’s not customizable. The keys and ranges generated dictate how the search will work. Whether you’re searching on both major and minor words, major word with minor initial, or something else is determined by the rules applied during integration.
Beyond these five preparatory steps, customers also have options when integrating around how the rules will execute. Different services can use their preferred rule tables. Additionally, weighting can be applied for particular comparisons like what to do when fields are blank.
Through these customizations, businesses can ensure that NameSearch is suited well to their organizational needs and the customer base that they serve. Given the wide range of potential variations due to typos, phonetic spellings, prefixes, suffixes, and so forth, a single matching approach is often insufficient. Altering these preparatory steps in the product’s settings prior to implementing the solution means that the customized version of NameSearch applies rules that will return the most accurate matches, capturing duplicates and correcting misinformation based on the type of data entered.
Contact us to learn more